When using MySQL you may need to ensure the availability or scalability of your MySQL installation. Availability refers to the ability to cope with, and if necessary recover from, failures on the host, including failures of MySQL, the operating system, or the hardware. Scalability refers to the ability to spread the load of your application queries across multiple MySQL servers. As your application and usage increases, you may need to spread the queries for the application across multiple servers to improve response times.
There are a number of solutions available for solving issues of availability and scalability. The two primary solutions supported by MySQL are MySQL Replication and MySQL Cluster. Further options are available using third-party solutions such as DRBD (Distributed Replicated Block Device) and Heartbeat, and more complex scenarios can be solved through a combination of these technologies. These tools work in different ways:
MySQL Replication enables statements and data from one MySQL server instance to be replicated to another MySQL server instance. Without using more complex setups, data can only be replicated from a single master server to any number of slaves. The replication is asynchronous, so the synchronization does not take place in real time, and there is no guarantee that data from the master will have been replicated to the slaves.
Advantages
MySQL Replication is available on all platforms supported by MySQL, and since it isn't operating system-specific it can operate across different platforms.
Replication is asynchronous and can be stopped and restarted at any time, making it suitable for replicating over slower links, partial links and even across geographical boundaries.
Data can be replicated from one master to any number of slaves, making replication suitable in environments with heavy reads, but light writes (for example, many web applications), by spreading the load across multiple slaves.
Disadvantages
Data can only be written to the master. In advanced configurations, though, you can set up a multiple-master configuration where the data is replicated around a ring configuration.
There is no guarantee that data on master and slaves will be consistent at a given point in time. Because replication is asynchronous there may be a small delay between data being written to the master and it being available on the slaves. This can cause problems in applications where a write to the master must be available for a read on the slaves (for example a web application).
Recommended uses
Scale-out solutions that require a large number of reads but fewer writes (for example, web serving).
Logging/data analysis of live data. By replicating live data to a slave you can perform queries on the slave without affecting the operation of the master.
Online backup (availability), where you need an active copy of the data available. You need to combine this with other tools, such as custom scripts or Heartbeat. However, because of the asynchronous architecture, the data may be incomplete.
Offline backup. You can use replication to keep a copy of the data. By replicating the data to a slave, you take the slave down and get a reliable snapshot of the data (without MySQL running), then restart MySQL and replication to catch up. The master (and any other slaves) can be kept running during this period.
For information on setting up and configuring replication, see Chapter 15, Replication.
MySQL Cluster is a synchronous solution that enables multiple MySQL instances to share database information. Unlike replication, data in a cluster can be read from or written to any node within the cluster, and information will be distributed to the other nodes.
Advantages
Offers multiple read and write nodes for data storage.
Provides automatic failover between nodes. Only transaction information for the active node being used is lost in the event of a failure.
Data on nodes is instantaneously distributed to the other data nodes.
Disadvantages
Available on a limited range of platforms.
Nodes within a cluster should be connected via a LAN; geographically separate nodes are not supported. However, you can replicate from one cluster to another using MySQL Replication, although the replication in this case is still asynchronous.
Recommended uses
Applications that need very high availability, such as telecoms and banking.
Applications that require an equal or higher number of writes compared to reads.
For information on MySQL Cluster, see Chapter 16, MySQL Cluster.
DRBD (Distributed Replicated Block Device) is a solution from Linbit supported only on Linux. DRBD creates a virtual block device (which is associated with an underlying physical block device) that can be replicated from the primary server to a secondary server. You create a filesystem on the virtual block device, and this information is then replicated, at the block level, to the secondary server.
Because the block device, not the data you are storing on it, is being replicated the validity of the information is more reliable than with data-only replication solutions. DRBD can also ensure data integrity by only returning from a write operation on the primary server when the data has been written to the underlying physical block device on both the primary and secondary servers.
Advantages
Provides high availability and data integrity across two servers in the event of hardware or system failure.
Ensures data integrity by enforcing write consistency on the primary and secondary nodes.
Disadvantages
Only provides a method for duplicating data across the nodes. Secondary nodes cannot use the DRBD device while data is being replicated, and so the MySQL on the secondary node cannot be simultaneously active.
Cannot provide scalability, since secondary nodes don't have access to the secondary data.
Recommended uses
High availability situations where concurrent access to the data is not required, but instant access to the active data in the event of a system or hardware failure is required.
For information on configuring DRBD and configuring MySQL for use with a DRBD device, see Section 14.1, “Using MySQL with DRBD for High Availability”.
Heartbeat is a software solution for Linux. It is not a data replication or synchronization solution, but a solution for monitoring servers and switching active MySQL servers automatically in the event of failure. Heartbeat needs to be combined with MySQL Replication or DRBD to provide automatic failover.
The information and suitability of the various technologies and different scenarios is summarized in the table below.
| Requirements | MySQL Replication | MySQL Replication + Heartbeat | MySQL Heartbeat + DRBD | MySQL Cluster |
|---|---|---|---|---|
| Availability | ||||
| Automated IP failover | No | Yes | Yes | No |
| Automated database failover | No | No | Yes | Yes |
| Typical failover time | User/script-dependent | Varies | < 30 seconds | < 3 seconds |
| Automatic resynchronization of data | No | No | Yes | Yes |
| Geographic redundancy support | Yes | Yes | Yes, when combined with MySQL Replication | Yes, when combined with MySQL Replication |
| Scalability | ||||
| Built-in load balancing | No | No | No | Yes |
| Supports Read-intensive applications | Yes | Yes | Yes, when combined with MySQL Replication | Yes |
| Supports Write-intensive applications | No | No | Yes | Yes |
| Maximum number of nodes per group | One master, multiple slaves | One master, multiple slaves | One active (primary), one passive (secondary) node | 255 |
| Maximum number of slaves | Unlimited (reads only) | Unlimited (reads only) | One (failover only) | Unlimited (reads only) |
The Distributed Replicated Block Device (DRBD) is a Linux Kernel module that constitutes a distributed storage system. You can use DRBD to share block devices between Linux servers and, in turn, share filesystems and data.
DRBD implements a block device which can be used for storage and which is replicated from a primary server to one or more secondary servers. The distributed block device is handled by the DRBD service. Writes to the DRBD block device are distributed among the servers. Each DRBD service writes the information from the DRBD block device to a local physical block device (hard disk).
On the primary, for example, the data writes are written both to the underlying physical block device and distributed to the secondary DRBD services. On the secondary, the writes received through DRBD and written to the local physical block device. On both the primary and the secondary, reads from the DRBD block device are handled by the underlying physical block device. The information is shared between the primary DRBD server and the secondary DRBD server synchronously and at a block level, and this means that DRBD can be used in high-availability solutions where you need failover support.
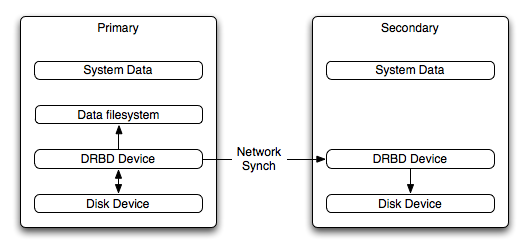
When used with MySQL, DRBD can be used to ensure availability in the event of a failure. MySQL is configured to store information on the DRBD block device, with one server acting as the primary and a second machine available to operate as an immediate replacement in the event of a failure.
For automatic failover support you can combine DRBD with the Linux Heartbeat project, which will manage the interfaces on the two servers and automatically configure the secondary (passive) server to replace the primary (active) server in the event of a failure. You can also combine DRBD with MySQL Replication to provide both failover and scalability within your MySQL environment.
For information on how to configure DRBD and MySQL, including Heartbeat support, see Section 14.1.1, “Configuring the DRBD Environment”.
An FAQ for using DRBD and MySQL is available. See Section A.14, “MySQL 5.0 FAQ — MySQL, DRBD, and Heartbeat”.
Note
Because DRBD is a Linux Kernel module it is currently not supported on platforms other than Linux.
To set up DRBD, MySQL and Heartbeat you need to follow a number of steps that affect the operating system, DRBD and your MySQL installation.
Before starting the installation process, you should be aware of the following information, terms and requirements on using DRBD:
DRBD is a solution for enabling high-availability, and therefore you need to ensure that the two machines within your DRBD setup are as identically configured as possible so that the secondary machine can act as a direct replacement for the primary machine in the event of system failure.
DRBD works through two (or more) servers, each called a node
The node that contains the primary data, has read/write access to the data, and in an HA environment is the currently active node is called the primary.
The server to which the data is replicated is referred as secondary.
A collection of nodes that are sharing information are referred to as a DRBD cluster.
For DRBD to operate you must have a block device on which the information can be stored on each DRBD node. The lower level block device can be a physical disk partition, a partition from a volume group or RAID device or any other block device.
Typically you use a spare partition on which the physical data will be stored . On the primary node, this disk will hold the raw data that you want replicated. On the secondary nodes, the disk will hold the data replicated to the secondary server by the DRBD service. Ideally, the size of the partition on the two DRBD servers should be identical, but this is not necessary as long as there is enough space to hold the data that you want distributed between the two servers.
For the distribution of data to work, DRBD is used to create a logical block device that uses the lower level block device for the actual storage of information. To store information on the distributed device, a filesystem is created on the DRBD logical block device.
When used with MySQL, once the filesystem has been created, you move the MySQL data directory (including InnoDB data files and binary logs) to the new filesystem.
When you set up the secondary DRBD server, you set up the physical block device and the DRBD logical block device that will store the data. The block device data is then copied from the primary to the secondary server.
The overview for the installation and configuration sequence is as follows:
First you need to set up your operating system and environment. This includes setting the correct hostname, updating the system and preparing the available packages and software required by DRBD, and configuring a physical block device to be used with the DRBD block device. See Section 14.1.1.1, “Setting Up the OS for DRBD”.
Installing DRBD requires installing or compiling the DRBD source code and then configuring the DRBD service to set up the block devices that will be shared. See Section 14.1.1.2, “Installing and Configuring DRBD”.
Once DRBD has been configured, you must alter the configuration and storage location of the MySQL data. See Section 14.1.2, “Configuring MySQL for DRBD”.
To set your Linux environment for using DRBD there are a number of system configuration steps that you must follow.
Make sure that the primary and secondary DRBD servers have the correct hostname, and that the hostnames are unique. You can verify this by using the uname command:
$ uname -n drbd-one
If the hostname is not set correctly then edit the appropriate file (usually
/etc/sysconfig/network,/etc/hostname, or/etc/conf.d/hostname) and set the name correctly.Each DRBD node must have a unique IP address. Make sure that the IP address information is set correctly within the network configuration and that the hostname and IP address has been set correctly within the
/etc/hostsfile.Although you can rely on the DNS or NIS system for host resolving, in the event of a major network failure these services may not be available. If possible, add the IP address and hostname of each DRBD node into the /etc/hosts file for each machine. This will ensure that the node information can always be determined even if the DNS/NIS servers are unavailable.
As a general rule, the faster your network connection the better. Because the block device data is exchanged over the network, everything that will be written to the local disk on the DRBD primary will also be written to the network for distribution to the DRBD secondary.
You must have a spare disk or disk partition that you can use as the physical storage location for the DRBD data that will be replicated. You do not have to have a complete disk available, a partition on an existing disk is acceptable.
If the disk is unpartitioned, partition the disk using fdisk, cfdisk or other partitioning solution.. Do not create a filesystem on the new partition.
Remember that you must have a physical disk available for the storage of the replicated information on each DRBD node. Ideally the partitions that will be used on each node should be of an identical size, although this is not strictly necessary. Do, however, ensure that the physical partition on the DRBD secondary is at least as big as the partitions on the DRBD primary node.
If possible, upgrade your system to the latest available Linux kernel for your distribution. Once the kernel has been installed, you must reboot to make the kernel active. To use DRBD you will also need to install the relevant kernel development and header files that are required for building kernel modules. Platform specification information for this is available later in this section.
Before you compile or install DRBD, you must make sure the following tools and files are in place:
Kernel header files
Kernel source files
GCC Compiler
glib 2flex
Here are some operating system specific tips for setting up your installation:
Tips for Red Hat (including CentOS and Fedora):
Use up2date or yum to update and install the latest kernel and kernel header files:
# up2date kernel-smp-devel kernel-smp
Reboot. If you are going to build DRBD from source, then update your system with the required development packages
# up2date glib-devel openssl-devel libgcrypt-devel glib2-devel \ pkgconfig ncurses-devel rpm-build rpm-devel redhat-rpm-config gcc \ gcc-c++ bison flex gnutls-devel lm_sensors-devel net-snmp-devel \ python-devel bzip2-devel libselinux-devel perl-DBI
If you are going to use the pre-built DRBD RPMs:
# up2date gnutls lm_sensors net-snmp ncurses libgcrypt glib2 openssl glib
Tips for Debian, Ubuntu, Kubuntu:
Use apt-get to install the kernel packages
# apt-get install linux-headers linux-image-server
If you are going to use the pre-built Debian packages for DRBD then you should not need any additional packages.
If you want to build DRBD from source, you will need to use the following command to install the required components:
# apt-get install devscripts flex bison build-essential \ dpkg-dev kernel-package debconf-utils dpatch debhelper \ libnet1-dev e2fslibs-dev libglib2.0-dev automake1.9 \ libgnutls-dev libtool libltdl3 libltdl3-dev
Tips for Gentoo:
Gentoo is a source based Linux distribution and therefore many of the source files and components that you will need are either already installed or will be installed automatically by emerge.
To install DRBD 0.8.x, you must unmask the
sys-cluster/drbdbuild by adding the following line to/etc/portage/package.keywords:sys-cluster/drbd ~x86 sys-cluster/drbd-kernel ~x86
If your kernel does not already have the userspace to kernelspace linker enabled, then you will need to rebuild the kernel with this option. The best way to do this is to use genkernel with the
--menuconfigoption to select the option and then rebuild the kernel. For example, at the command line asroot:# genkernel --menuconfig all
Then through the menu options, select , and finally press 'y' or 'space' to select the option. Then exit the menu configuration. The kernel will be rebuilt and installed. If this is a new kernel, make sure you update your bootloader accordingly. Now reboot to enable the new kernel.
You can now emerge DRBD 0.8.x into your Gentoo installation:
# emerge drbd
Once
drbdhas been downloaded and installed, you need to decompress and copy the default configuration file from/usr/share/doc/drbd-8.0.7/drbd.conf.bz2into/etc/drbd.conf.
To install DRBD you can choose either the pre-built binary installation packages or you can use the source packages and build from source. If you want to build from source you must have installed the source and development packages.
If you are installing using a binary distribution then you must ensure that the kernel version number of the binary package matches your currently active kernel. You can use uname to find out this information:
$ uname -r 2.6.20-gentoo-r6
To build from the sources, download the source
tar.gz package, extract the contents and then
follow the instructions within the INSTALL
file.
Once DRBD has been built and installed, you need to edit the
/etc/drbd.conf file and then run a number
of commands to build the block device and set up the
replication.
Although the steps below are split into those for the primary node and the secondary node, it should be noted that the configuration files for all nodes should be identical, and many of the same steps have to be repeated on each node to enable the DRBD block device.
To set up a DRBD primary node you need to configure the DRBD service, create the first DRBD block device and then create a filesystem on the device so that you can store files and data.
The DRBD configuration file
(/etc/drbd.conf) defined a number of
parameters for your DRBD configuration, including the frequency
of updates and block sizes, security information and the
definition of the DRBD devices that you want to create.
The key elements to configure are the on
sections which specify the configuration of each node.
To follow the configuration, the sequence below shows only the
changes from the default drbd.conf file.
Configurations within the file can be both global or tied to
specific resource.
Set the synchronization rate between the two nodes. This is the rate at which devices are synchronized in the background after a disk failure, device replacement or during the initial setup. You should keep this in check compared to the speed of your network connection. Gigabit Ethernet can support up to 125 MB/second, 100Mbps Ethernet slightly less than a tenth of that (12MBps). If you are using a shared network connection, rather than a dedicated, then you should gauge accordingly.
For more detailed information on synchronization, the effects of the synchronization rate and the effects on network performance, see Section 14.1.3.2, “Optimizing the Synchronization Rate”.
To set the synchronization rate, edit the
ratesetting within thesyncerblock:syncer { rate 10M; }Set up some basic authentication. DRBD supports a simple password hash exchange mechanism. This helps to ensure that only those hosts with the same shared secret are able to join the DRBD node group.
cram-hmac-alg “sha1”; shared-secret "
shared-string";Now you must configure the host information. Remember that you must have the node information for the primary and secondary nodes in the
drbd.conffile on each host. You need to configure the following information for each node:device— the path of the logical block device that will be created by DRBD.disk— the block device that will be used to store the data.address— the IP address and port number of the host that will hold this DRBD device.meta-disk— the location where the metadata about the DRBD device will be stored. You can set this tointernaland DRBD will use the physical block device to store the information, by recording the metadata within the last sections of the disk. The exact size will depend on the size of the logical block device you have created, but it may involve up to 128MB.
A sample configuration for our primary server might look like this:
on drbd-one { device /dev/drbd0; disk /dev/hdd1; address 192.168.0.240:8888; meta-disk internal; }The
onconfiguration block should be repeated for the secondary node (and any further) nodes:on drbd-two { device /dev/drbd0; disk /dev/hdd1; address 192.168.0.241:8888; meta-disk internal; }The IP address of each
onblock must match the IP address of the corresponding host. Do not set this value to the IP address of the corresponding primary or secondary in each case.Before starting the primary node, you should create the metadata for the devices:
# drbdadm create-md all
You are now ready to start DRBD:
# /etc/init.d/drbd start
DRBD should now start and initialize, creating the DRBD devices that you have configured.
DRBD creates a standard block device - to make it usable, you must create a filesystem on the block device just as you would with any standard disk partition. Before you can create the filesystem, you must mark the new device as the primary device (i.e. where the data will be written and stored), and initialize the device. Because this is a destructive operation, you must specify the command line option to overwrite the raw data:
# drbdadm -- --overwrite-data-of-peer primary all
If you are using a version of DRBD 0.7.x or earlier, then you need to use a different command-line option:
# drbdadm -- --do-what-I-say primary all
Now create a filesystem using your chosen filesystem type:
# mkfs.ext3 /dev/drbd0
You can now mount the filesystem and if necessary copy files to the mount point:
# mkdir /mnt/drbd # mount /dev/drbd0 /mnt/drbd # echo "DRBD Device" >/mnt/drbd/samplefile
Your primary node is now ready to use. You should now configure your secondary node or nodes.
The configuration process for setting up a secondary node is the same as for the primary node, except that you do not have to create the filesystem on the secondary node device, as this information will automatically be transferred from the primary node.
To set up a secondary node:
Copy the
/etc/drbd.conffile from your primary node to your secondary node. It should already contain all the information and configuration that you need, since you had to specify the secondary node IP address and other information for the primary node configuration.Create the DRBD metadata on the underlying disk device:
# drbdadm create-md all
Start DRBD:
# /etc/init.d/drbd start
Once DRBD has started, it will start the copy the data from the primary node to the secondary node. Even with an empty filesystem this will take some time, since DRBD is copying the block information from a block device, not simply copying the filesystem data.
You can monitor the progress of the copy between the primary and
secondary nodes by viewing the output of
/proc/drbd:
# cat /proc/drbd
version: 8.0.4 (api:86/proto:86)
SVN Revision: 2947 build by root@drbd-one, 2007-07-30 16:43:05
0: cs:SyncSource st:Primary/Secondary ds:UpToDate/Inconsistent C r---
ns:252284 nr:0 dw:0 dr:257280 al:0 bm:15 lo:0 pe:7 ua:157 ap:0
[==>.................] sync'ed: 12.3% (1845088/2097152)K
finish: 0:06:06 speed: 4,972 (4,580) K/sec
resync: used:1/31 hits:15901 misses:16 starving:0 dirty:0 changed:16
act_log: used:0/257 hits:0 misses:0 starving:0 dirty:0 changed:0
Once the primary and secondary machines are configured and
synchronized, you can get the status information about your DRBD
device by viewing the output from
/proc/drbd:
# cat /proc/drbd
version: 8.0.4 (api:86/proto:86)
SVN Revision: 2947 build by root@drbd-one, 2007-07-30 16:43:05
0: cs:Connected st:Primary/Secondary ds:UpToDate/UpToDate C r---
ns:2175704 nr:0 dw:99192 dr:2076641 al:33 bm:128 lo:0 pe:0 ua:0 ap:0
resync: used:0/31 hits:134841 misses:135 starving:0 dirty:0 changed:135
act_log: used:0/257 hits:24765 misses:33 starving:0 dirty:0 changed:33The first line provides the version/revision and build information.
The second line starts the detailed status information for an individual resource. The individual field headings are as follows:
cs — connection state
st — node state (local/remote)
ld — local data consistency
ds — data consistency
ns — network send
nr — network receive
dw — disk write
dr — disk read
pe — pending (waiting for ack)
ua — unack'd (still need to send ack)
al — access log write count
In the previous example, the information shown indicates that the nodes are connected, the local node is the primary (because it is listed first), and the local and remote data is up to date with each other. The remainder of the information is statistical data about the device, and the data exchanged that kept the information up to date.
For administration, the main command is drbdadm. There are a number of commands supported by this tool the control the connectivity and status of the DRBD devices.
The most common commands are those to set the primary/secondary status of the local device. You can manually set this information for a number of reasons, including when you want to check the physical status of the secondary device (since you cannot mount a DRBD device in primary mode), or when you are temporarily moving the responsibility of keeping the data in check to a different machine (for example, during an upgrade or physical move of the normal primary node). You can set state of all local device to be the primary using this command:
# drbdadm primary all
Or switch the local device to be the secondary using:
# drbdadm secondary all
To change only a single DRBD resource, specify the resource name
instead of all.
You can temporarily disconnect the DRBD nodes:
# drbdadm disconnect all
Reconnect them using connect:
# drbdadm connect all
For other commands and help with drbdadm see the DRBD documentation.
Additional options you may want to configure:
protocol— specifies the level of consistency to be used when information is written to the block device. The option is similar in principle to theinnodb_flush_log_at_trx_commitoption within MySQL. Three levels are supported:A— data is considered written when the information reaches the TCP send buffer and the local physical disk. There is no guarantee that the data has been written to the remote server or the remote physical disk.B— data is considered written when the data has reached the local disk and the remote node's network buffer. The data has reached the remote server, but there is no guarantee it has reached the remote server's physical disk.C— data is considered written when the data has reached the local disk and the remote node's physical disk.
The preferred and recommended protocol is C, as it is the only protocol which ensures the consistency of the local and remote physical storage.
size— if you do not want to use the entire partition space with your DRBD block device then you can specify the size of the DRBD device to be created. The size specification can include a quantifier. For example, to set the maximum size of the DRBD partition to 1GB you would use:size 1G;
With the configuration file suitably configured and ready to use, you now need to populate the lower-level device with the metadata information, and then start the DRBD service.
Once you have configured DRBD and have an active DRBD device and filesystem, you can configure MySQL to use the chosen device to store the MySQL data.
When performing a new installation of MySQL, you can either select to install MySQL entirely onto the DRBD device, or just configure the data directory to be located on the new filesystem.
In either case, the files and installation must take place on the primary node, because that is the only DRBD node on which you can mount the DRBD device filesystem as read/write.
You should store the following files and information on your DRBD device:
MySQL data files, including the binary log, and InnoDB data files.
MySQL configuration file (
my.cnf).
To set up MySQL to use your new DRBD device and filesystem:
If you are migrating an existing MySQL installation, stop MySQL:
$ mysqladmin shutdown
Copy the
my.cnfonto the DRBD device. If you are not already using a configuration file, copy one of the sample configuration files from the MySQL distribution.# mkdir /mnt/drbd/mysql # cp /etc/my.cnf /mnt/drbd/mysql
Copy your MySQL data directory to the DRBD device and mounted filesystem.
# cp -R /var/lib/mysql /drbd/mysql/data
Edit the configuration file to reflect the change of directory by setting the value of the
datadiroption. If you have not already enabled the binary log, also set the value of thelog-binoption.datadir = /drbd/mysql/data log-bin = mysql-bin
Create a symbolic link from
/etc/my.cnfto the new configuration file on the DRBD device filesystem.# ln -s /drbd/mysql/my.cnf /etc/my.cnf
Now start MySQL and check that the data that you copied to the DRBD device filesystem is present.
# /etc/init.d/mysql start
Your MySQL data should now be located on the filesystem running on your DRBD device. The data will be physically stored on the underlying device that you configured for the DRBD device. Meanwhile, the content of your MySQL databases will be copied to the secondary DRBD node.
Note that you cannot access the information on your secondary node, as a DRBD device working in secondary mode is not available for use.
Because of the nature of the DRBD system, the critical requirements are for a very fast exchange of the information between the two hosts. To ensure that your DRBD setup is available to switch over in the event of a failure as quickly as possible, you must transfer the information between the two hosts using the fastest method available.
Typically, a dedicated network circuit should be used for exchanging DRBD data between the two hosts. You should then use a separate, additional, network interface for your standard network connection. For an example of this layout, see Figure 14.2, “DRBD Architecture”.
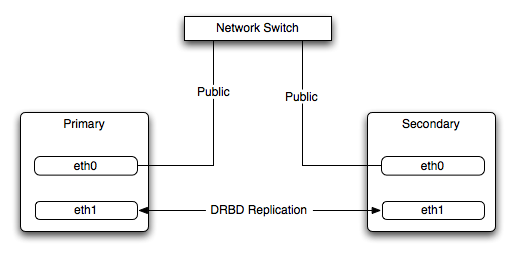
The dedicated DRBD network interfaces should be configured to use a non-routed TCP/IP network configuration. For example, you might want to set the primary to use 192.168.0.1 and the secondary 192.168.0.2. These networks and IP addresses should not be part of normal network subnet.
Note
The preferred setup, whenever possible, is to use a direct cable connection (using a crossover cable with Ethernet, for example) between the two machines. This eliminates the risk of loss of connectivity due to switch failures.
For a set-up where there is a high-throughput of information being written, you may want to use bonded network interfaces. This is where you combine the connectivity of more than one network port, increasing the throughput linearly according to the number of bonded connections.
Bonding also provides an additional benefit in that with multiple network interfaces effectively supporting the same communications channel, a fault within a single network interface in a bonded group does not stop communication. For example, imagine you have a bonded setup with four network interfaces providing a single interface channel between two DRBD servers. If one network interface fails, communication can continue on the other three without interruption, although it will be at a lower speed
To enable bonded connections you must enable bonding within the kernel. You then need to configure the module to specify the bonded devices and then configure each new bonded device just as you would a standard network device:
To configure the bonded devices, you need to edit the
/etc/modprobe.conffile (RedHat) or add a file to the/etc/modprobe.ddirectory.. In each case you will define the parameters for the kernel module. First, you need to specify each bonding device:alias bond0 bonding
You can then configure additional parameters for the kernel module. Typical parameters are the
modeoption and themiimonoption.The
modeoption specifies how the network interfaces are used. The default setting is 0, which means that each network interface is used in a round-robin fashion (this supports aggregation and fault tolerance). Using setting 1 sets the bonding mode to active-backup. This means that only one network interface is used as a time, but that the link will automatically failover to a new interface if the primary interface fails. This settings only supports fault-tolerance.The
miimonoption enables the MII link monitoring. A positive value greater than zero indicates the monitoring frequency in milliseconds for checking each slave network interface that is configured as part of the bonded interface. A typical value is 100.You set th options within the module parameter file, and you must set the options for each bonded device individually:
options bond0 miimon=100 mode=1
Reboot your server to enable the bonded devices.
Configure the network device parameters. There are two parts to this, you need to setup the bonded device configuration, and then configure the original network interfaces as 'slaves' of the new bonded interface.
For RedHat Linux:
Edit the configuration file for the bonded device. For device
bond0this would be/etc/sysconfig/network-scripts/ifcfg-bond0:DEVICE=bond0 BOOTPROTO=none ONBOOT=yes GATEWAY=192.168.0.254 NETWORK=192.168.0.0 NETMASK=255.255.255.0 IPADDR=192.168.0.1 USERCTL=no
Then for each network interface that you want to be part of the bonded device, configure the interface as a slave to the 'master' bond. For example, the configuration of
eth0in/etc/sysconfig/network-scripts/ifcfg-eth0might look like this::DEVICE=eth0 BOOTPROTO=none HWADDR=00:11:22:33:44:55 ONBOOT=yes TYPE=Ethernet MASTER=bond0 SLAVE=yes
For Debian Linux:
Edit the
/etc/iftabfile and configure the logical name and MAC address for each devices. For example:eth0 mac 00:11:22:33:44:55
Now you need to set the configuration of the devices in
/etc/network/interfaces:auto bond0 iface bond0 inet static address 192.168.0.1 netmask 255.255.255.0 network 192.168.0.0 gateway 192.168.0.254 up /sbin/ifenslave bond0 eth0 up /sbin/ifenslave bond0 eth1For Gentoo:
Use emerge to add the
net-misc/ifenslavepackage to your system.Edit the
/etc/conf.d/netfile and specify the network interface slaves in a bond, the dependencies and then the configuration for the bond itself. A sample configuration might look like this:slaves_bond0="eth0 eth1 eth2" config_bond0=( "192.168.0.1 netmask 255.255.255.0" ) depend_bond0() { need net.eth0 net.eth1 net.eth2 }Then make sure that you add the new network interface to list of interfaces configured during boot:
# rc-update add default net.bond0
Once the bonded devices are configured you should reboot your systems.
You can monitor the status of a bonded connection using the
/proc filesystem:
# cat /proc/net/bonding/bond0 Bonding Mode: fault-tolerance (active-backup) Primary Slave: None Currently Active Slave: eth1 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 200 Down Delay (ms): 200 Slave Interface: eth1 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:11:22:33:44:55 Slave Interface: eth2 MII Status: up Link Failure Count: 0 Permanent HW addr: 00:11:22:33:44:56
The syncer rate configuration parameter
should be configured with care as the synchronization rate can
have a significant effect on the performance of the DRBD setup
in the event of a node or disk failure where the information is
being synchronized from the Primary to the Secondary node.
In DRBD, there are two distinct ways of data being transferred between peer nodes:
Replication refers to the transfer of modified blocks being transferred from the primary to the secondary node. This happens automatically when the block is modified on the primary node, and the replication process uses whatever bandwidth is available over the replication link. The replication process cannot be throttled, because you want to transfer of the block information to happen as quickly as possible during normal operation.
Synchronization refers to the process of bringing peers back in sync after some sort of outage, due to manual intervention, node failure, disk swap, or the initial setup. Synchronization is limited to the
syncer rateconfigured for the DRBD device.
Both replication and synchronization can take place at the same time. For example, the block devices can be being synchronized while they are actively being used by the primary node. Any I/O that updates on the primary node will automatically trigger replication of the modified block. In the event of a failure within an HA environment, it is highly likely that synchronization and replication will take place at the same time.
Unfortunately, if the synchronization rate is set too high, then the synchronization process will use up all the available network bandwidth between the primary and secondary nodes. In turn, the bandwidth available for replication of changed blocks is zero, which means replication will stall and I/O will block, and ultimately the application will fail or degrade.
To avoid enabling the syncer rate to consume
the available network bandwidth and prevent the replication of
changed blocks you should set the syncer rate
to less than the maximum network bandwidth.
Depending on the application, you may wish to limit the synchronization rate. For example, on a busy server you may wish to configure a significantly slower synchronization rate to ensure the replication rate is not affected.
The Heartbeat program provides a basis for verifying the availability of resources on one or more systems within a cluster. In this context a resource includes MySQL, the filesystems on which the MySQL data is being stored and, if you are using DRBD, the DRBD device being used for the filesystem. Heartbeat also manages a virtual IP address, and the virtual IP address should be used for all communication to the MySQL instance.
A cluster within the context of Heartbeat is defined as two computers notionally providing the same service. By definition, each computer in the cluster is physically capable of providing the same services as all the others in the cluster. However, because the cluster is designed for high-availability, only one of the servers is actively providing the service at any one time. Each additional server within the cluster is a 'hot-spare' that can be brought into service in the event of a failure of the master, it's next connectivity or the connectivity of the network in general.
The basics of Heartbeat are very simple. Within the Heartbeat cluster (see Figure 14.3, “DRBD Architecture”, each machine sends a 'heartbeat' signal to the other hosts in the cluster. The other cluster nodes monitor this heartbeat. The heartbeat can be transmitted over many different systems, including shared network devices, dedicated network interfaces and serial connections. Failure to get a heartbeat from a node is treated as failure of the node. Although we don't know the reason for the failure (it could be an OS failure, a hardware failure in the server, or a failure in the network switch), it is safe to assume that if no heartbeat is produced there is a fault.
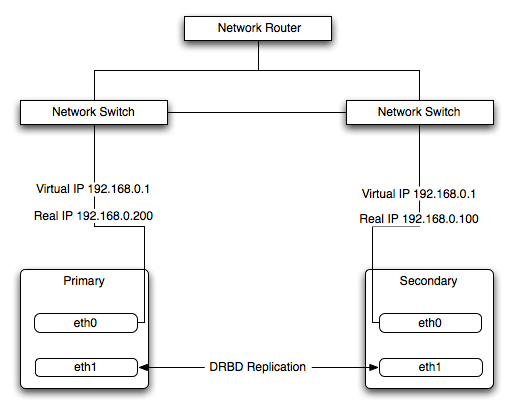
In addition to checking the heartbeat from the server, the system can also check the connectivity (using ping) to another host on the network, such as the network router. This allows Heartbeat to detect a failure of communication between a server and the router (and therefore failure of the server, since it is no longer capable of providing the necessary service), even if the heartbeat between the servers in the clusters is working fine.
In the event of a failure, the resources on the failed host are disabled, and the resources on one of the replacement hosts is enabled instead. In addition, the Virtual IP address for the cluster is redirected to the new host in place of the failed device.
When used with MySQL and DRBD, the MySQL data is replicated from the master to the slave using the DRBD device, but MySQL is only running on the master. When the master fails, the slave switches the DRBD devices to be primary, the filesystems on those devices are mounted, and MySQL is started. The original master (if still available) has it's resources disabled, which means shutting down MySQL and unmounting the filesystems and switching the DRBD device to secondary.
Heartbeat configuration requires three files located in
/etc/ha.d. The ha.cf
contains the main heartbeat configuration, including the list of
the nodes and times for identifying failures.
haresources contains the list of resources to
be managed within the cluster. The authkeys
file contains the security information for the cluster.
The contents of these files should be identical on each host within the Heartbeat cluster. It's important that you keep these files in sync across all the hosts. Any changes in the information on one host should be copied to the all the others.
For these examples n example of the ha.cf
file is shown below:
logfacility local0 keepalive 500ms deadtime 10 warntime 5 initdead 30 mcast bond0 225.0.0.1 694 2 0 mcast bond1 225.0.0.2 694 1 0 auto_failback off node drbd1 node drbd2
The individual lines in the file can be identified as follows:
logfacility— sets the logging, in this case setting the logging to use syslog.keepalive— defines how frequently the heartbeat signal is sent to the other hosts.deadtime— the delay in seconds before other hosts in the cluster are considered 'dead' (failed).warntime— the delay in seconds before a warning is written to the log that a node cannot be contacted.initdead— the period in seconds to wait during system startup before the other host is considered to be down.mcast— defines a method for sending a heartbeat signal. In the above example, a multicast network address is being used over a bonded network device. If you have multiple clusters then the multicast address for each cluster should be unique on your network. Other choices for the heartbeat exchange exist, including a serial connection.If you are using multiple network interfaces (for example, one interface for your server connectivity and a secondary and/or bonded interface for your DRBD data exchange) then you should use both interfaces for your heartbeat connection. This decreases the chance of a transient failure causing a invalid failure event.
auto_failback— sets whether the original (preferred) server should be enabled again if it becomes available. Switching this toonmay cause problems if the preferred went offline and then comes back on line again. If the DRBD device has not been synced properly, or if the problem with the original server happens again you may end up with two different datasets on the two servers, or with a continually changing environment where the two servers flip-flop as the preferred server reboots and then starts again.node— sets the nodes within the Heartbeat cluster group. There should be onenodefor each server.
An optional additional set of information provides the
configuration for a ping test that will check the connectivity to
another host. You should use this to ensure that you have
connectivity on the public interface for your servers, so the ping
test should be to a reliable host such as a router or switch. The
additional lines specify the destination machine for the
ping, which should be specified as an IP
address, rather than a hostname; the command to run when a failure
occurs, the authority for the failure and the timeout before an
non-response triggers a failure. A sample configure is shown
below:
ping 10.0.0.1 respawn hacluster /usr/lib64/heartbeat/ipfail apiauth ipfail gid=haclient uid=hacluster deadping 5
In the above example, the ipfail command, which
is part of the Heartbeat solution, is called on a failure and
'fakes' a fault on the currently active server. You need to
configure the user and group ID under which the command should be
executed (using the apiauth). The failure will
be triggered after 5 seconds.
Note
The deadping value must be less than the
deadtime value.
The auth_keys file holds the authorization
information for the Heartbeat cluster. The authorization relies on
a single unique 'key' that is used to verify the two machines in
the Heartbeat cluster. It is used only to confirm that the two
machines are in the same cluster and is used to ensure that the
To use Heartbeat in combination with MySQL you should be using DRBD (see Section 14.1, “Using MySQL with DRBD for High Availability”) or another solution that allows for sharing of the MySQL database files in event of a system failure. In these examples, DRBD is used as the data sharing solution.
Heartbeat manages the configuration of different resources to manage the switching between two servers in the event of a failure. The resource configuration defines the individual services that should be brought up (or taken down) in the event of a failure.
The haresources file within
/etc/ha.d defines the resources that should
be managed, and the individual resource mentioned in this file in
turn relates to scripts located within
/etc/ha.d/resource.d. The resource definition
is defined all on one line:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 mysql 10.0.0.100
The line is notionally split by whitespace. The first entry
(drbd1) is the name of the preferred host, i.e.
the server that is normally responsible for handling the service.
The last field is virtual IP address or name that should be used
to share the service. This is the IP address that should be used
to connect to the MySQL server. It will automatically be allocated
to the server that is active when Heartbeat starts.
The remaining fields between these two fields define the resources
that should be managed. Each Field should contain the name of the
resource (and each name should refer to a script within
/etc/ha.d/resource.d). In the event of a
failure, these resources are started on the backup server by
calling the corresponding script (with a single argument,
start), in order from left to right. If there
are additional arguments to the script, you can use a double colon
to separate each additional argument.
In the above example, we manage the following resources:
drbddisk— the DRBD resource script, this will switch the DRBD disk on the secondary host into primary mode, making the device read/write.Filesystem— manages the Filesystem resource. In this case we have supplied additional arguments to specify the DRBD device, mount point and filesystem type. When executed this should mount the specified filesystem.mysql— manages the MySQL instances and starts the MySQL server. You should copy themysql.resourcefile from thesupport-filesdirectory from any MySQL release into the/etc/ha.d/resources.ddirectory.
If you want to be notified of the failure by email, you can add
another line to the haresources file with the
address for warnings and the warning text:
MailTo::youremail@address.com::DRBDFailure
With the Heartbeat configuration in place, copy the
haresources, authkeys
and ha.cf files from your primary and
secondary servers to make sure that the configuration is
identical. Then start the Heartbeat service, either by calling
/etc/init.d/heartbeat start or by rebooting
both primary and secondary servers.
You can test the configuration by running a manual failover, connect to the primary node and run:
# /usr/lib64/heartbeat/hb_standby
This will cause the current node to relinquish its resources cleanly to the other node.
As a further extension to using DRBD and Heartbeat together, you can enable dopd. The dopd daemon handles the situation where a DRBD node is out of date compared to the master and prevents the slave from being promoted to master in the event of a failure. This stops a situation where you have two machines that have been masters ending up different data on the underlying device.
For example, imagine that you have a two server DRBD setup, master and slave. If the DRBD connectivity between master and slave fails then the slave would be out of the sync with the master. If Heartbeat identifies a connectivity issue for master and then switches over to the slave, the slave DRBD device will be promoted to the primary device, even though the data on the slave and the master is not in synchronization.
In this situation, with dopd enabled, the
connectivity failure between the master and slave would be
identified and the metadata on the slave wold be set to
Outdated. Heartbeat will then refuse to switch
over to the slave even if the master failed. In a dual-host
solution this would effectively render the cluster out of action,
as there is no additional fail over server. In an HA cluster with
three or more servers, control would be passed to the slave that
has an up to date version of the DRBD device data.
To enable dopd, you need to modify the
Heartbeat configuration and specify dopd as
part of the commands executed during the monitoring process. Add
the following lines to your ha.cf file:
respawn hacluster /usr/lib/heartbeat/dopd apiauth dopd gid=haclient uid=hacluster
Make sure you make the same modification on both your primary and secondary nodes.
You will need to reload the Heartbeat configuration:
# /etc/init.d/heartbeat reload
You will also need to modify your DRBD configuration by
configuration the outdate-peer option. You will
need to add the configuration line into the
common section of
/etc/drbd.conf on both hosts. An example of
the full block is shown below:
common {
handlers {
outdate-peer "/usr/lib/heartbeat/drbd-peer-outdater";
}
}
Finally, set the fencing option on your DRBD
configured resources:
resource my-resource {
disk {
fencing resource-only;
}
}Now reload your DRBD configuration:
# drbdadmin adjust all
You can test the system by unplugging your DRBD link and
monitoring the output from /proc/drbd.
Because a kernel panic or oops may indicate potential problem with your server, you should configure your server to remove itself from the cluster in the event of a problem. Typically on a kernel panic your system will automatically trigger a hard reboot. For a kernel oops a reboot may not happen automatically, but the issue that caused that oops may still lead to potential problems.
You can force a reboot by setting the
kernel.panic and
kernel.panic_on_oops parameters of the kernel
control file /etc/sysctl.conf. For example:
kernel.panic_on_oops = 1 kernel.panic = 1
You can also set these parameters during runtime by using the sysctl command. You can either specify the parameters on the command line:
$ sysctl -w kernel.panic=1
Or you can edit your sysctl.conf file and
then reload the configuration information:
$ sysctl -p
By setting both these parameters to a positive value (actually the number of seconds to wait before triggering the reboot), the system will reboot. Your second heartbeat node should then detect that the server is down and then switch over to the failover host.